In this introduction, we will explore the concept of VACUUM in PostgreSQL, its importance, and best practices for implementing effective vacuuming strategies to ensure your database remains efficient, performant, and reliable. Before we dive into strategies, problem detection and so on, it is important to understand why VACUUM is needed in the first place.
Table of Contents
VACUUM will always exist in PostgreSQL and many myths have formed around it. Therefore, it is important to shed some light on why VACUUM is necessary. The reason why VACUUM is so relevant can be summed up in one word and one word only: “Transactions”.
Why is that the case? Consider the following example:
| Transaction 1 | Transaction 2 |
| SELECT count(*) FROM tab; | |
| … returns 0 … | |
| BEGIN; | |
| INSERT INTO table VALUES (1), (2), (3); | |
| SELECT count(*) FROM tab; | SELECT count(*) FROM tab; |
| … returns 3 … | … returns 0 … |
| ROLLBACK; | ← 3 rows are now eliminated |
What is important to understand is that our two sessions will see different data. The left session will actually see 3 rows, while the right session, happening at the same time, won’t see any rows because the left transaction has not been committed yet.
The question naturally arising is: How can we get rid of those 3 rows that are subject to our ROLLBACK? In contrast to MS SQL and Oracle, PostgreSQL does NOT remove those rows from disk during a ROLLBACK. That is the reason why ROLLBACK is lightning fast in PostgreSQL and usually a real pain in MS SQL (in case of large transactions).
The job of VACUUM is to clean out those rows as soon as a row cannot be seen by any active transaction anymore. Here is a picture that shows how this works:
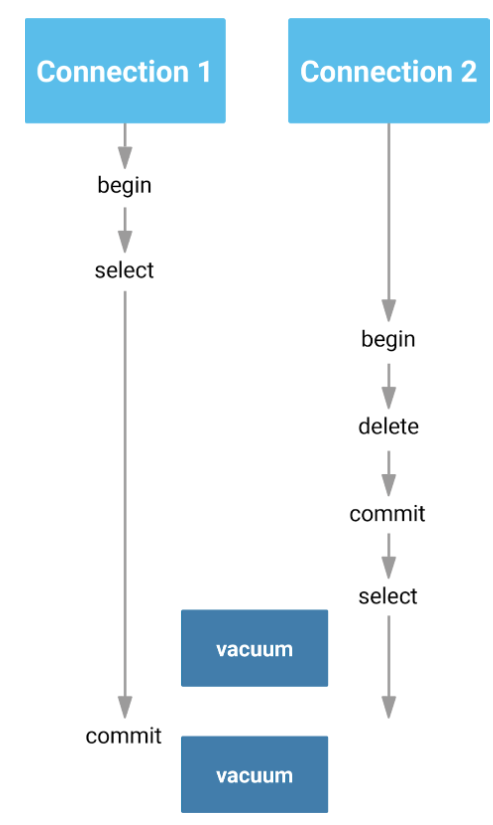
In this case (as outlined in our blog about VACUUM and hot_standby_feedback), the first VACUUM will NOT remove rows from disk because the transaction on the left side can still see the data. There are some key takeaways in this example one should be aware of:
Running VACUUM is therefore not enough - it is also necessary to give VACUUM a change to actually do something. Getting rid of long transactions is therefore key to success.
The classical question people ask our PostgreSQL support teams are:
The following example will try to shed some light here:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
test=# CREATE TABLE t_vacuum ( id int, x char(1500) DEFAULT 'abc' ); CREATE TABLE test=# INSERT INTO t_vacuum SELECT id FROM generate_series(1, 30) AS id; INSERT 0 30 test=# SELECT ctid, id FROM t_vacuum; ctid | id -------+---- (0,1) | 1 (0,2) | 2 (0,3) | 3 (0,4) | 4 (0,5) | 5 (1,1) | 6 (1,2) | 7 (1,3) | 8 (1,4) | 9 (1,5) | 10 (2,1) | 11 (2,2) | 12 … (5,3) | 28 (5,4) | 29 (5,5) | 30 (30 rows) |
We have created a table which consists of 30 really large rows (each of them > 1.500 bytes). This means that only 5 rows will fit into an 8k block in PostgreSQL. To see which row is where, we can make use of a hidden column called “ctid”. It contains the number of the block as well as the row inside the block (ctid = ‘(2, 4)’ means the third block, 4th row). What happens if we delete a row and run VACUUM? Before we do that, we can enable some extensions to actually see what is going on inside our table:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
test=# CREATE EXTENSION pg_freespacemap; CREATE EXTENSION test=# SELECT * FROM pg_freespace('t_vacuum'); blkno | avail -------+------- 0 | 448 1 | 448 2 | 448 3 | 448 4 | 448 5 | 0 (6 rows) |
This extension allows us to find out how much space happens to be in each of our 8k blocks. In this case, we are talking about 448 bytes per block. The reason is that a row has to fit into a single block (in this case).
Now that we understand what has happened, we can delete some data and see what is going on:
|
1 2 3 4 5 6 7 8 9 10 |
test=# DELETE FROM t_vacuum WHERE id = 7 OR id = 8 RETURNING ctid; ctid ------- (1,2) (1,3) (2 rows) DELETE 2 |
What we see here is a gap in the data file:
|
1 2 3 4 5 6 7 8 9 10 |
test=# SELECT ctid, id FROM t_vacuum WHERE id BETWEEN 5 AND 10; ctid | id -------+---- (0,5) | 5 (1,1) | 6 (1,4) | 9 (1,5) | 10 (4 rows) |
Rows (1, 2) and (1, 3) are gone (= marked as dead). What we need to understand is that the data is basically dead on disk. If we take a look at the content of the freespace map, we can see that it has not changed:
|
1 2 3 4 5 6 7 8 9 10 |
test=# SELECT * FROM pg_freespace('t_vacuum'); blkno | avail -------+------- 0 | 448 1 | 448 2 | 448 3 | 448 4 | 448 5 | 0 (6 rows) |
This is an important takeaway: space is NOT freed when data is deleted - space is reclaimed by VACUUM:
|
1 2 |
test=# VACUUM t_vacuum; VACUUM |
Once VACUUM has been executed (assuming that no long running transaction is blocking it from doing its work), the freespace map (= FSM) is going to reflect the new reality on disk:
|
1 2 3 4 5 6 7 8 9 10 |
test=# SELECT * FROM pg_freespace('t_vacuum'); blkno | avail -------+------- 0 | 448 1 | 3520 2 | 448 3 | 448 4 | 448 5 | 448 (6 rows) |
Note that we still have 5 blocks - the difference is that now the second block has much more free space. A normal VACUUM will not move data between blocks - that is simply the way it is. Therefore, space is not returned to the operating system (filesystem). But it doesn't matter much because in the vast majority of cases we want to use it later anyway:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
test=# INSERT INTO t_vacuum VALUES (999, 'abcdefg') RETURNING ctid; ctid ------- (1,2) (1 row) INSERT 0 1 test=# VACUUM ; VACUUM test=# SELECT * FROM pg_freespace('t_vacuum'); blkno | avail -------+------- 0 | 448 1 | 1984 2 | 448 3 | 448 4 | 448 5 | 448 (6 rows) |
As we can see, the next write will fill the gaps and re-allocate the space for us. This is important because it means that returning space to the filesystem (operating system) would be a temporary thing anyway after a VACUUM FULL. The next writer operation would immediately ask for more filesystem space anyway. In reality, VACUUM FULL is way less important than people think. Quite the contrary: It can cause issues because it needs a harsh table lock. I ‘m not saying that VACUUM FULL is pointless - what I am saying here is that it is used way too often.
As mentioned already, the problem with VACUUM FULL is that it needs a table lock. In many cases, this essentially means “downtime”. If you cannot write data to a table, it basically means that your application is no longer usable.
An alternative to this is pg_squeeze. It is an Open Source tool that can be added via package manager to reorganize tables without excessive locking. It allows you to reorganize a table without blocking writes during the process.
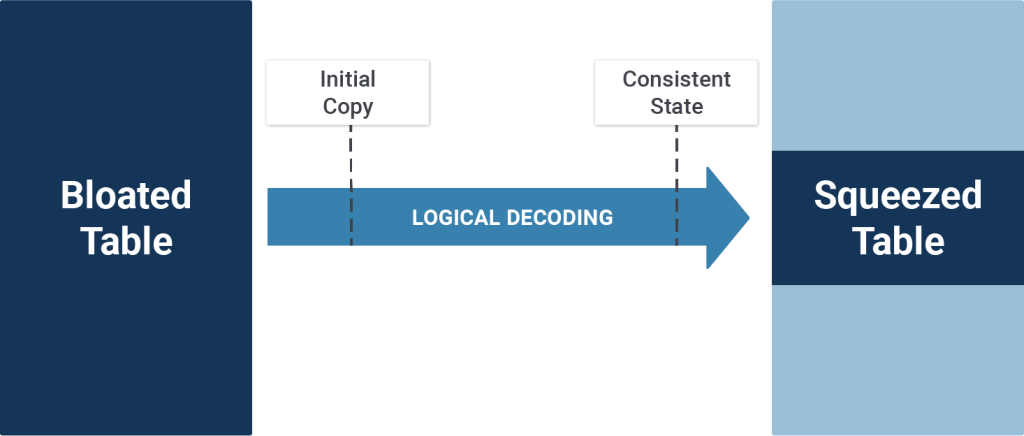
The way it works is to take an initial (small) copy of the data in the table (excluding bloat) and apply the changes happening during that initial copy. At the end of the process, the data files are swapped out in the system catalog, leading to minimal locking (just milliseconds).
The main issue is that before we start to fight bloat, it is a good idea to actually find out which tables are bloated and which ones are not. Doing this for a single table can be done using the pgstattuple extension which is part of the PostgreSQL contrib package. Here’s how it works:
|
1 2 |
test=# CREATE EXTENSION pgstattuple; CREATE EXTENSION |
First of all, we have to enable the extension. Then, we will again create some sample data:
|
1 2 3 4 |
test=# CREATE TABLE t_bloat AS SELECT id FROM generate_series(1, 1000000) AS id; SELECT 1000000 |
The table has been fully populated, but let’s see what happens when some of the data is deleted:
|
1 2 3 4 |
test=# DELETE FROM t_bloat WHERE id < 50000; DELETE 49999 test=# VACUUM t_bloat; VACUUM |
By calling pgstattuple, we can inspect the table and find out what our data files consist of. The output of pgstattuple is a fairly broad table, so we can use \x to make the output more digestible:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
test=# \x Expanded display is on. test=# SELECT * FROM pgstattuple('t_bloat'); -[ RECORD 1 ]------+--------- table_len | 36700160 tuple_count | 950001 tuple_len | 26600028 tuple_percent | 72.48 dead_tuple_count | 0 dead_tuple_len | 0 dead_tuple_percent | 0 free_space | 1925452 free_percent | 5.25 |
What can we see here? First of all we can see the size of our data file (table_len) and the number of rows in the table (tuple_count). We will also see the amount of dead space (dead_tuple_len) as well as the amount of free space in the table. Remember: “valid + dead + free = table size”. The important aspect is that those values should be in a useful ratio. Depending on the type of application, this may of course vary and therefore it is not useful to dogmatically stick to a fixed threshold of “what is good” and “what is bad”.
However, we have to keep one thing in mind: The pgstattuple function scans the entire table. In other words, if your table is 25 TB you will read 25 TB - just to get those numbers. In real life this can be a huge problem. To solve the problem, PostgreSQL offers the pgstattuple_approx function which does not read the entire table but instead takes a sample. Here’s how it works:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
test=# SELECT * FROM pgstattuple_approx('t_bloat'); -[ RECORD 1 ]--------+------------------- table_len | 36700160 scanned_percent | 1.2276785714285714 approx_tuple_count | 950001 approx_tuple_len | 34442720 approx_tuple_percent | 93.84896414620536 dead_tuple_count | 0 dead_tuple_len | 0 dead_tuple_percent | 0 approx_free_space | 2256120 approx_free_percent | 6.147439139229911 |
The function executes a lot faster and gives us deep insights.
So far you have learned to run pgstattuple for a single table. But how can we do that for all tables in our database?
Here is a query that might be useful:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT a.oid::regclass AS table_name, b.* FROM (SELECT oid FROM pg_class WHERE oid > 16384 AND relkind = 'r') AS a, LATERAL (SELECT * FROM pgstattuple_approx(a.oid) AS c ) AS b ORDER BY 2 DESC; |
Without going into the details of why we should use LATERAL and so on, here is what the output might look like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
-[ RECORD 1 ]--------+----------------------- table_name | t_test table_len | 1812389888 scanned_percent | 0 approx_tuple_count | 50000000 approx_tuple_len | 1812389376 approx_tuple_percent | 99.99997175000792 dead_tuple_count | 0 dead_tuple_len | 0 dead_tuple_percent | 0 approx_free_space | 512 approx_free_percent | 2.8249992090002215e-05 -[ RECORD 2 ]--------+----------------------- table_name | t_bloat table_len | 36700160 scanned_percent | 1.2276785714285714 approx_tuple_count | 950001 approx_tuple_len | 34442720 approx_tuple_percent | 93.84896414620536 dead_tuple_count | 0 dead_tuple_len | 0 dead_tuple_percent | 0 approx_free_space | 2256120 approx_free_percent | 6.147439139229911 … |
The query will return all non-system tables in our database and inspect them one by one. The list is ordered (largest tables first). This will give us valuable insights into the structure and content of our data files associated with those tables.
There is an important aspect related to VACUUM that is often overlooked: many people think that shrinking tables is beneficial under all circumstances. However, this is not necessarily true. In case your tables are facing many UPDATE statements, it might be beneficial to use a thing called FILLFACTOR. The idea is to not completely fill up your 8k blocks, but instead leave some space for UPDATEs to put the copy of a row into the same block. Using this strategy, we can avoid some I/O and make things more efficient. In the past, we have written some blog posts on those issues:
We recommend taking a look at these articles to gain more understanding regarding this topic.
Still, let’s revert back to the first table we created and see why this matters:
|
1 2 3 4 5 |
test=# TRUNCATE t_vacuum ; TRUNCATE TABLE test=# INSERT INTO t_vacuum SELECT id FROM generate_series(1, 10) AS id; INSERT 0 10 |
The listing empties the table and adds 10 new large rows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
test=# SELECT ctid, id FROM t_vacuum; ctid | id -------+---- (0,1) | 1 (0,2) | 2 (0,3) | 3 (0,4) | 4 (0,5) | 5 (1,1) | 6 (1,2) | 7 (1,3) | 8 (1,4) | 9 (1,5) | 10 (10 rows) |
What we see is that two blocks have been tightly packed together. This means that UPDATE cannot simply keep the copy it has to create within the same block. Therefore, we have to touch the first block containing the updated row and write a new one containing the new version:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
test=# UPDATE t_vacuum SET id = 100 WHERE id = 1; UPDATE 1 test=# SELECT ctid, id FROM t_vacuum; ctid | id -------+----- (0,2) | 2 (0,3) | 3 (0,4) | 4 (0,5) | 5 (1,1) | 6 (1,2) | 7 (1,3) | 8 (1,4) | 9 (1,5) | 10 (2,1) | 100 (10 rows) |
In other words, we had to touch two blocks just to update a single row. The situation changes when there is still some space left inside the block as we can see in the next example:
|
1 2 3 4 5 6 7 8 9 10 11 |
test=# UPDATE t_vacuum SET id = 999 WHERE id = 100; UPDATE 1 test=# SELECT ctid, id FROM t_vacuum; ctid | id -------+----- (0,2) | 2 … (1,4) | 9 (1,5) | 10 (2,2) | 999 (10 rows) |
We notice that only block number three has changed. ctid ‘(2,1)’ is gone, and the copy has been placed into ‘(2, 2)’ which is the same block. Only half of the disk I/O was necessary. By setting a clever FILLFACTOR (= usually somewhere between 60 and 80), we can make this type of UPDATE (= within the same block) more likely:
|
1 2 |
test=# ALTER TABLE t_vacuum SET (FILLFACTOR=60); ALTER TABLE |
As you can see, the size of a table does matter in many cases but sometimes, it can also be a little counterproductive (which is counterintuitive for many people). Still, some basic understanding is needed to tune those things.
If you want to learn more about PostgreSQL and COMMIT in particular, I recommend checking our post on PostgreSQL COMMIT performance.
It would be nice to list one of the main complex bloat checker SQLs that would bypass the need to use the more expensive pgstattuple module.
This is of course a matter of taste, but I personally would not use those queries. They are trying to guess, and they have false positive as well as false negative results.
The
pgstattuple_approx()function is a compromise.If you are looking for these queries, they are only a web search away. From what I remember,
check_postgres.plhas one.Good points, although pgstattuple_approx ignores toast table bloat. Only the regular one takes into account toast table bloat.