PostgreSQL replication is not just a way to scale your database to run ever larger workloads: it's also a way to make your database infrastructure redundant, more reliable and resilient. There is, however, a potential for replication lag, which needs to be monitored. How can you monitor replication lag in PostgreSQL? What is replication lag? And how can you monitor PostgreSQL replication in general?
Let's dive in and find out.
Table of Contents
For the sake of this example, I have set up a database server (PostgreSQL 16) and a single replica.
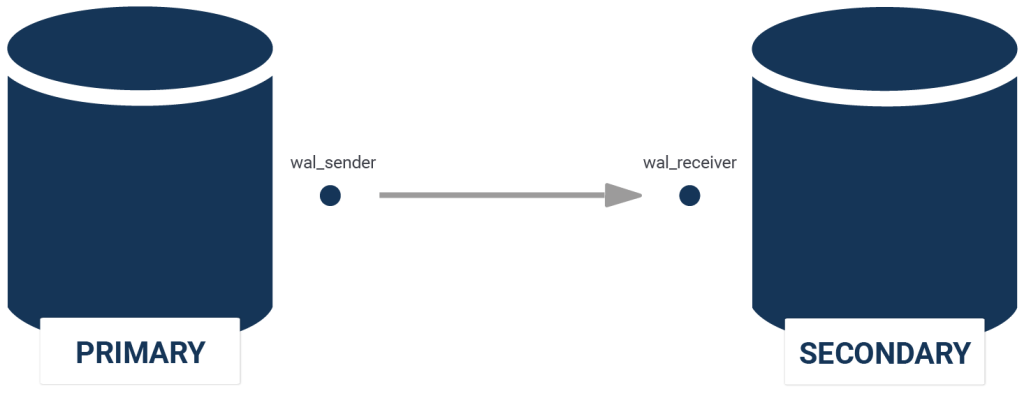
When monitoring replication delay and replication lag, look at the system view called pg_stat_replication. It contains all the information you’ll need to identify and diagnose replication problems. Here’s what the view looks like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
postgres=# d pg_stat_replication View 'pg_catalog.pg_stat_replication' Column | Type | Collation | Nullable | Default ------------------+--------------------------+-----------+----------+--------- pid | integer | | | usesysid | oid | | | usename | name | | | application_name | text | | | client_addr | inet | | | client_hostname | text | | | client_port | integer | | | backend_start | timestamp with time zone | | | backend_xmin | xid | | | state | text | | | sent_lsn | pg_lsn | | | write_lsn | pg_lsn | | | flush_lsn | pg_lsn | | | replay_lsn | pg_lsn | | | write_lag | interval | | | flush_lag | interval | | | replay_lag | interval | | | sync_priority | integer | | | sync_state | text | | | reply_time | timestamp with time zone | | | |
Technically, this is information about the “WAL sender”. What does that mean? When two PostgreSQL servers communicate, the sending machine undergoes a “WAL sender” process, while the receiving machine undergoes a “WAL receiver” process. The pg_stat_replication view tells us all we need to know about the “WAL senders” (= 1 per destination). The view contains data when ask for information from a primary - but it also contains information in case of cascading replication when you ask a replica to pass data to other replicas.
In the case of cascading replication, a machine in the middle will have one or more WAL sender(s) as well as a WAL receiver:
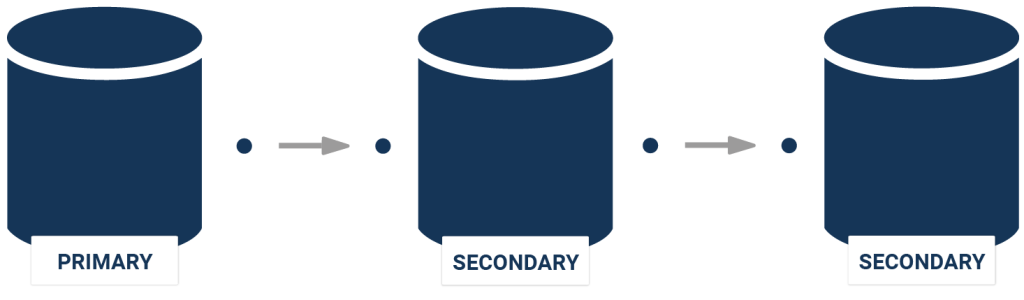
In this case, the setup is easy: A single server will stream to a secondary one on the same machine. Let's take a look and see what happens here:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
postgres=# x Expanded display is on. postgres=# SELECT * FROM pg_stat_replication; -[ RECORD 1 ]----+------------------------------ pid | 48929 usesysid | 10 usename | hs application_name | walreceiver client_addr | ::1 client_hostname | client_port | 61445 backend_start | 2023-08-01 10:53:48.068431+02 backend_xmin | state | streaming sent_lsn | 0/303C750 write_lsn | 0/303C750 flush_lsn | 0/303C750 replay_lsn | 0/303C750 write_lag | flush_lag | replay_lag | sync_priority | 0 sync_state | async reply_time | 2023-08-01 10:55:00.783736+02 |
The fact that there is one entry in the system view tells us that there is one ACTIVE stream. Note that we are talking about active streams - in case a stream that is supposed to be there is not active, there is no entry. In other words: Check for the existence of the row to validate that streaming is indeed active.
What is also important is the state of the stream. If all is normal you can identify the stream as “streaming”. However, you might also see “catchup” or some other state in case your server is still syncing.
The basic check is therefore: Ensure that the right processes are correctly aimed at the right replication target.
Once this is done, we need to take a deeper look at the *_lsn columns. There are four, and it’s important to understand them:
To understand what's going on here, we need to inspect the flow of data in the first place:
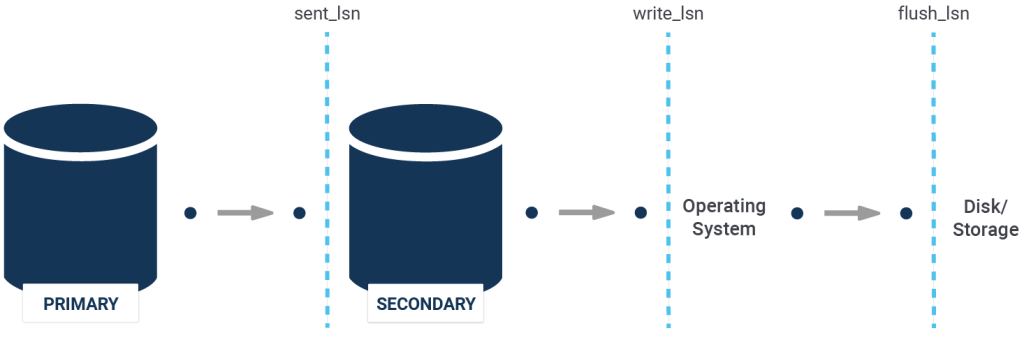
When data flows from one server to another, it reaches the second server through the WAL-receiver. This is the “sent_lsn” (or “sent_location” as it used to be called in older versions of PostgreSQL).
Once data has reached the second server it will be processed and sent to the operating system. PostgreSQL will ask the kernel to write the data. However, this does not mean that the data has actually hit the disk - it only means that we have sent data to the file system which might end up caching things. In this case, we are talking about the “write_lsn” - it is the position in the transaction log stream which has made it to the disk already.
The next relevant number is “flush_lsn”.
write_lsn and flush_lsn?write_lsn tells us how much data has been sent to the kernel - flush_lsn tells us how much data has been flushed already. Writing to a file does not mean that data has indeed reached the storage device. Flushing ensures that data will survive a power outage.
replay_lsnFinally, there is replay_lsn. This value causes a lot of confusion. It can happen that a transaction has made it to disk on the replica but it might not be visible to end users yet. This is even true in case of synchronous replication. Yes, you read that correctly. Synchronous replication usually does NOT guarantee that you can see data on the replica which was committed on the primary. How can that happen? The answer is: During a replication conflict the replica might write and flush a transaction to disk, but not apply the change yet before the conflict ends (check this link out for details). In a nutshell, replay_lsn will tell you how much data is already visible.
pg_stat_wal_receiverSo far we have inspected what we can do on the WAL sender side. There is also a view named pg_stat_wal_receiver. Not surprisingly, it covers the receiving end of things:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
postgres=# d pg_stat_wal_receiver View 'pg_catalog.pg_stat_wal_receiver' Column | Type | Collation | Nullable | Default -----------------------+--------------------------+-----------+----------+--------- pid | integer | | | status | text | | | receive_start_lsn | pg_lsn | | | receive_start_tli | integer | | | written_lsn | pg_lsn | | | flushed_lsn | pg_lsn | | | received_tli | integer | | | last_msg_send_time | timestamp with time zone | | | last_msg_receipt_time | timestamp with time zone | | | latest_end_lsn | pg_lsn | | | latest_end_time | timestamp with time zone | | | slot_name | text | | | sender_host | text | | | sender_port | integer | | | conninfo | text | | | |
However, this one is far harder to read. I prefer using pg_stat_replication to make monitoring easier.
A replication slot ensures that the WAL will not go away if the replica lags behind. Without a replication slot, a primary will recycle its WAL as soon as it doesn’t need it on its own anymore.
The system view to check for stale replication slots is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
postgres=# d pg_replication_slots View 'pg_catalog.pg_replication_slots' Column | Type | Collation | Nullable | Default ---------------------+---------+-----------+----------+--------- slot_name | name | | | plugin | name | | | slot_type | text | | | datoid | oid | | | database | name | | | temporary | boolean | | | active | boolean | | | active_pid | integer | | | xmin | xid | | | catalog_xmin | xid | | | restart_lsn | pg_lsn | | | confirmed_flush_lsn | pg_lsn | | | wal_status | text | | | safe_wal_size | bigint | | | two_phase | boolean | | | conflicting | boolean | | | |
Make sure that there are no pending replication slots which are stale and not needed anymore. Any of those should be dropped.
Hi Hans, nice blog! Thank you for sharing it.
The first item in the "Table Of Contents" appeared with text from the blog paragraph in my FF browser 🙂