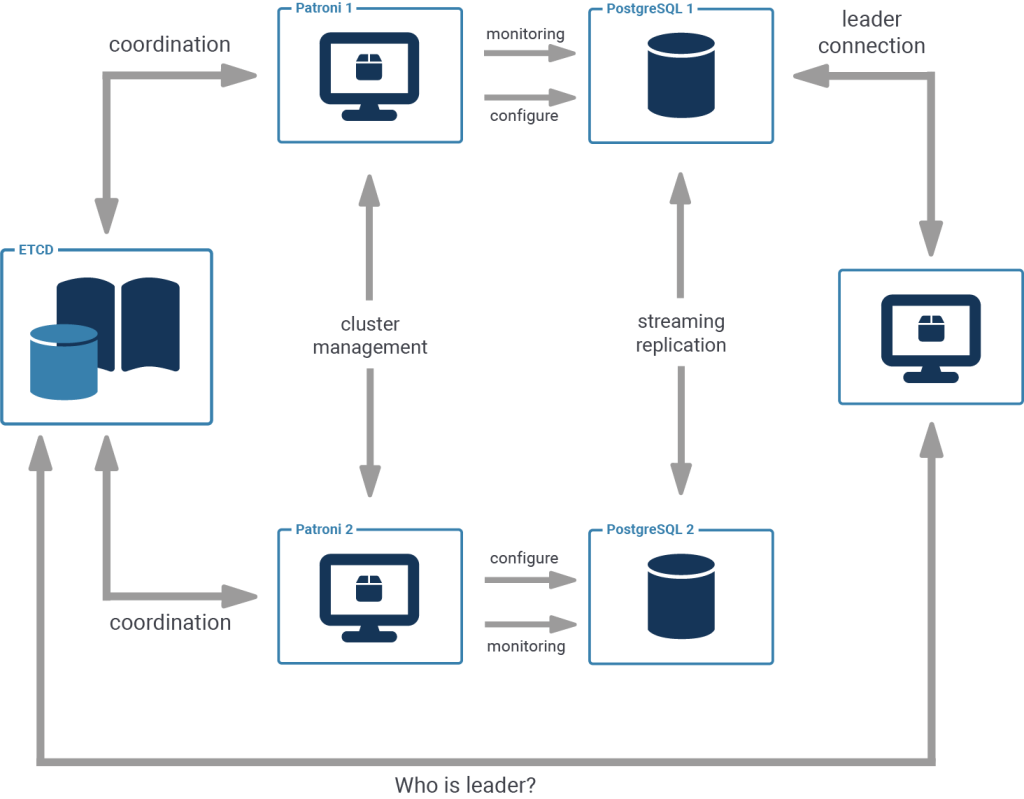
Patroni is a cluster manager used to customize and automate deployment and maintenance of PostgreSQL HA (High Availability) clusters. It uses distributed configuration stores like etcd, Consul, ZooKeeper or Kubernetes for maximum accessibility.
Table of Contents
In this tutorial, we will be using a single local etcd instance and two local Patroni instances on a single host instead of a more complex multi-host setup.
I assume that you’re comfortable with PostgreSQL Streaming Replication, so let’s proceed with the installation.
If you're not sure what this all is about, I highly recommend giving this brief introduction a read:
PostgreSQL High-Availability and Patroni – an Introduction.
A Patroni cluster requires not only executables for Patroni, but also for PostgreSQL of some version (at least 9.5 or above) and the configuration store of your choice (we'll use etcd).
Cybertec provides .rpm packages of Patroni 1.6.0 for both Fedora 30 and CentOS/RHEL 7 on Github.
|
1 2 3 4 5 6 7 |
# install postgresql.org repo dnf install https://download.postgresql.org/pub/repos/yum/reporpms/F-30-x86_64/pgdg-fedora-repo-latest.noarch.rpm dnf install postgresql11 postgresql11-server dnf install etcd # get patroni package from github wget https://github.com/cybertec-postgresql/patroni-packaging/releases/download/1.6.0-1/patroni-1.6.0-1.fc30.x86_64.rpm dnf install patroni-1.6.0-1.fc30.x86_64.rpm |
|
1 2 3 4 5 6 7 8 9 |
# install postgresql.org repo yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm yum install postgresql11 postgresql11-server yum install etcd #install epel, for python36-psycopg2 needed by patroni yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm # get patroni package from github wget https://github.com/cybertec-postgresql/patroni-packaging/releases/download/1.6.0-1/patroni-1.6.0-1.rhel7.x86_64.rpm dnf install patroni-1.6.0-1.rhel7.x86_64.rpm |
|
1 2 3 4 5 |
# Ubuntu 19.04 and Debian Buster already have PostgreSQL 11 apt update apt install --no-install-recommends postgresql-11 postgresql-client-11 apt install etcd apt install patroni |
Here we start a single member etcd cluster.
This etcd will listen to client requests on port 2379 and stores data in the default directory: ./default.etcd .
|
1 |
etcd > etcd_logfile 2>&1 & |
To check the etcd member list, run:
|
1 |
etcdctl member list |
Please be aware that this is only a basic setup guide. In a production environment, a single member etcd cluster would be a problematic failure point. If that etcd stops working, Patroni would have to stop the primary and secondary PostgreSQL instances.
There will be another post describing the details of etcd and how to set up clusters containing at least three members, which should be the minimum for a production setup.
Everything that we create and modify from now on should be done by the user postgres, as postgres should own the config files, data directories and the Patroni and PostgreSQL processes.
Each Patroni instance needs its own config file. This config file tells it where to contact the DCS (Distributed Configuration Store - etcd in our case), where and how to start the database and how to configure it.
For simplicity, sample config files are provided for this tutorial for both Debian/Ubuntu and Fedora/RHEL/CentOS.
The REST API port and postgresql port are different in the config file for the second cluster member to avoid conflicts since we are running two members on the same host.
Please note that the provided config files differ in two aspects: the directory that contains binaries for PostgreSQL and the directory that contains your database's data.
So please, use the files that match your distribution, as shown in the wget calls below.
To start both nodes:
|
1 2 3 4 5 |
sudo -iu postgres wget https://download.cybertec-postgresql.com/patroni_example_configs/rhel_patroni_1.yml wget https://download.cybertec-postgresql.com/patroni_example_configs/rhel_patroni_2.yml patroni rhel_patroni_1.yml > patroni_member_1.log 2>&1 & patroni rhel_patroni_2.yml > patroni_member_2.log 2>&1 & |
Before starting the Patroni cluster, make sure the default PostgreSQL cluster has been stopped and disabled.
This can usually be done with a service postgresql stop .
|
1 2 3 4 5 |
sudo -iu postgres wget https://download.cybertec-postgresql.com/patroni_example_configs/deb_patroni_1.yml wget https://download.cybertec-postgresql.com/patroni_example_configs/deb_patroni_2.yml patroni deb_patroni_1.yml > patroni_member_1.log 2>&1 & patroni deb_patroni_2.yml > patroni_member_2.log 2>&1 & |
If you examine the produced logfiles, you will find that one of the patroni processes has bootstrapped (i.e. ran initdb) and started as a leader.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
2019-07-30 13:45:45,168 INFO: Selected new etcd server http://localhost:2379 2019-07-30 13:45:45,193 INFO: Lock owner: None; I am member_1 2019-07-30 13:45:45,198 INFO: trying to bootstrap a new cluster ... 2019-07-30 13:45:47,260 INFO: postmaster pid=25866 ... 2019-07-30 13:45:48,328 INFO: establishing a new patroni connection to the postgres cluster 2019-07-30 13:45:48,336 INFO: running post_bootstrap 2019-07-30 13:45:48,361 INFO: initialized a new cluster 2019-07-30 13:45:58,350 INFO: Lock owner: member_1; I am member_1 2019-07-30 13:45:58,360 INFO: Lock owner: member_1; I am member_1 2019-07-30 13:45:58,437 INFO: no action. i am the leader with the lock 2019-07-30 13:46:08,351 INFO: Lock owner: member_1; I am member_1 2019-07-30 13:46:08,362 INFO: no action. i am the leader with the lock |
The other process noticed that there is already another leader and configured itself to receive streaming replication from it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
2019-07-30 13:45:52,751 INFO: Selected new etcd server http://localhost:2379 2019-07-30 13:45:52,783 INFO: Lock owner: member_1; I am member_2 2019-07-30 13:45:52,784 INFO: Lock owner: member_1; I am member_2 2019-07-30 13:45:52,787 INFO: trying to bootstrap from leader 'member_1' 2019-07-30 13:45:54,616 INFO: replica has been created using basebackup 2019-07-30 13:45:54,618 INFO: bootstrapped from leader 'member_1' 2019-07-30 13:45:54,643 INFO: postmaster pid=25897 ... 2019-07-30 13:45:56,725 INFO: Lock owner: member_1; I am member_2 2019-07-30 13:45:56,731 INFO: Lock owner: member_1; I am member_2 2019-07-30 13:45:56,731 INFO: does not have lock 2019-07-30 13:45:56,731 INFO: establishing a new patroni connection to the postgres cluster 2019-07-30 13:45:56,747 INFO: no action. i am a secondary and i am following a leader 2019-07-30 13:45:58,365 INFO: Lock owner: member_1; I am member_2 2019-07-30 13:45:58,366 INFO: does not have lock 2019-07-30 13:45:58,369 INFO: no action. i am a secondary and i am following a leader |
Check the status of the cluster with patronictl:
|
1 2 3 4 5 6 7 8 |
patronictl -d etcd://localhost:2379 list patroni_cluster_1 +---------+-------------+----------------+--------+---------+----+-----------+ | Cluster | Member | Host | Role | State | TL | Lag in MB | +---------+-------------+----------------+--------+---------+----+-----------+ | patroni_cluster_1 | member_1 | 127.0.0.1:5432 | Leader | running | 1 | 0.0 | | patroni_cluster_1 | member_2 | 127.0.0.1:5433 | | running | 1 | 0.0 | +---------+-------------+----------------+--------+---------+----+-----------+ |
Now you can simply connect to your new database using the port where your cluster's leader currently is:
|
1 |
psql -p 5432 -h 127.0.0.1 |
The steps above can be easily modified to create a cluster that spans several hosts.
Just change the IP addresses for the advertised and initial cluster arguments for etcd and for Patroni and PostgreSQL in the Patroni config files and make sure that all necessary ports are opened, if you're running systems with a firewall.
Once the key concept of Patroni is well understood, it is easy to deploy and manage bigger clusters.
This post is part of a series.
Besides this post the following articles have already been published:
– PostgreSQL High-Availability and Patroni – an Introduction.
The series will also cover:
– setting up multi-member etcd clusters
– configuration and troubleshooting
– failover, maintenance, and monitoring
– client connection handling and routing
– WAL archiving and database backups using pgBackrest
– PITR a patroni cluster using pgBackrest
etcd is working with 2 nodes? Where is the quorum? At least there should be 2n 1 (where n is expected failure (default to 1)). I'd prefer Consul with Raft instead. 😉
You're right. But, in this example, one instance of etcd is running.
And this is not an instruction for action in the production environment, it is rather an example of a quick launch in a test environment to get acquainted with how it works.
By the way, my choice is etcd 🙂
There is one etcd only in this tutorial.
This is only a very basic example to get you started experimenting with Patroni...
I've got another blog planned where I'll show two ways of starting etcd clusters with at least 3 nodes.
A disclaimer on running etcd in single node mode was just added to the blog post!
Thanks for the remark!
If you're not sure how to setup a consul cluster, I can write a post on that as well...
But then it won't be long before I'll have to write one for every DCS that can be used as a key-value store for Patroni 🙂
I meant two database nodes, not the etcd one. A cluster with two database nodes doesn't have a quorum. 😉 I am already using Consul because the former etcd "now you'll have to use api v2.. And now you'll have to use api v3" was a major pain. But that is the great advantage of open source: you can use what fits best for your needs.
Great articles; looking forward for the next one.
(BTW: I think Patroni is using the service discovery feature of Consul by registering as a service so you won't need a vip by using Consul as additional DNS resolver and connecting to a service address instead. But not sure about it. Maybe you have more insides of the code and workflow of Patroni.)
There is no need to have a quorum between database cluster members (i.e. the different postgresql-instances), as there is never more than a single member that will accept writes (the primary).
To guarantee that this never happens (split brain...), patroni uses a DCS.
Etcd allows write operations to all members, and thus, etcd has to run it's own quorum.
Thus, the number of patroni/postgresql instances has no impact on the possibility of split-brain. That number is only dependant on your own evaluation of the likelihood of member failure and how many read-replicas you deem necessary.
I agree that the policy of etcd could be a little nicer; We've been plagued with version switches as well. Thankfully, etcd 3.4 can be configured to still run in v2 mode:
--enable-v2orETCD_ENABLE_V2=trueThe service discovery feature of consul is something I'll need to look into...
Here's the relevant Pull-request:
https://github.com/zalando/patroni/pull/802
For etcd, we usually use vip-manager to handle client traffic routing:
https://github.com/cybertec-postgresql/vip-manager
From my experience, every customer has different needs regarding routing/discovery/pooling and so on...So the more solutions there are, the better.
Hi, are the packages fine as i am getting errrors now while downloading it.
File contains parsing errors: file:///etc/yum.repos.d/pgdg-redhat-all.repo
[line 196]: [pgdg96-updates-debuginfo]k
[line 203]: [pgdg95-updates-debuginfo]k
Hey, I'm sorry you're experiencing issues, I'm not exactly sure what the issue here is...
have you installed the pgdg repo freshly or was it already present on your system?
I can still install the pgdg repo and Patroni rpm in a fresh install of CentOS 7, no problems...
On second look, it just seems to me that you need to get rid of those 'k' at the end of the section headers you pasted:
[pgdg96-updates-debuginfo]k
should simply be
[pgdg96-updates-debuginfo]
its sorted , thanks a lot for help.
Awsome document, which backup methodology you recommend for PITR with Patroni ?
I'm glad you liked it.
I've had a good experience using pgBackRest, it is aware of replicas by default. You just list all of the database cluster members and pgBackRest will itself figure out who is the primary when you try to pull a backup.
WAL-archival and restoring works great as well, so no issues with PITR.
But you need to fully understand the subject of PITR on a managed high-availability cluster.
So you need to pause cluster management in Patroni, stop the primary, stop the replicas, do PITR on the primary, then start the primary, then the simplest option is to reinitialize the replica from the primary using patroni (internally done with pg_basebackup usually).
We offer support for all of that. Maybe I'm going to write another blog post that covers the basics of Patroni pgBackRest, but please don't expect it to be anytime soon...
Thanks a lot, I am thinking for backup solution as taking pg_basebackup once in a week and keeping wal's for rest of day , this will also suffice the requirement of PITR with patroni or specifically pgbackrest does something which i cannot achieve via pg_basebackup ? i found points like incremental and parallel backups but keeping WAL will solve incremental problem and found .pgpass as another flaw with pg_basebackup to make it automated it will give another file with hardcoded username/passwords.
Thanks a lot for all the help.
pgBackRest has a nice overview where it lists all full/incremental/differential backups, size, creation time, it shows archived WAL segments all within a single command.
You can run a single pgBackRest repository to manage backups and WAL archives for several different clusters simultaneously.
pgBackRest will make sure to retrieve the appropriate backup for a given PITR recovery - say you create a backup at the evening of day 1 and another one on the evening of day 2. on day 3, you want to PITR to some moment in the morning on day 2. Which with pg_basebackup means you manually need to look for the appropriate backup.
With pgBackRest, you simply specify the target time to pgBackRest restore command and it will pick the right backup as needed.
I have not considered testing pg_basebackup or anything else for regular backups as pgBackRest has a high convenience and also low barrier to entry, I think.
If you have some time, I suggest you just try it out, here are two blog posts that I found very helpful:
https://pgstef.github.io/2018/01/04/introduction_to_pgbackrest.html
https://pgstef.github.io/2018/11/28/combining_pgbackrest_and_streaming_replication.html
Finally, if you decide to do only weekly backups, you should test how much WAL is generated...If you take a backup from Sunday and need to PITR using WAL to the following Friday, depending on the amount of traffic on your database, will mean that the database has to potentially recover *and* apply hundreds of gigabytes of WAL. For high-traffic environments I'd rather use incremental/differential daily backups and a full backup for a week. Almost a whole day of WAL could still take some time to reapply...
Hi julian, im new to patroni and postgresql, i have pgbackrest setup on my master-slave using postgresql12 /centos 7. May i know how to setup patroni ha for auto-failover use and switchback. Can i have sample step by step for this setup? I want to use patroni for our ha. Thank you.
Cenon roxas
Email: cenon_roxas@yahoo.com
Dear Cenon, I've answered your request by mail.
I hope you can understand that a step by step guide will be too much for the scope of this blog. At the same time, there are many differences in production setups, so without knowing more about your setup, I can't give more than a broad guide.
I will try to write another blog post at some time, giving a general guide on patroni and pgbackrest, but in the meantime, I'm sure we can help you out!
Hello Julian,
Can you please send me how to setup patroni ha for auto-failover use and switchback with pgbackrest.
Thank you
Email: rabeb.soltani@esprit.tn
Nice Article . I have 2 new Node Red Hat server with PostgreSQL 12 , can i use Patroni for HA and Automatic failover ? Can you send me some step by step guide for implementing Patroni .
Sumit.usr@gmail.com
Dear Sumit,
the article already contains detailed instructions on how to set up Patroni on RH7 machines as well as a set of configuration files you can use. Prior to that, you will need to setup an etcd cluster, I wrote a blogpost about that as well:
https://www.cybertec-postgresql.com/introduction-and-how-to-etcd-clusters-for-patroni/
If you're using RH8, it's a bit more difficult, currently we do not provide an RPM for RH8, but you could use the one provided by postgresql.org, see the following yum repo:
https://yum.postgresql.org/common/redhat/rhel-8-x86_64/
Another challenge on RH8 is that there is no etcd package available. You could download the binary release from etcd directly and install it in your system, or use a container solution to rig up an etcd cluster.
If you require help beyond what I can offer on this blog, please send an email to office@cybertec.at and we will make sure to help you swiftly.
Best regards
Julian
Hi Julian. Thanks for writing this blog. its very much helpful for me to set up a 2 node pg cluster using patroni and etcd. Could you please help me in identifying a solution with adding another tool for connection pooling like 'pgbouncer'. i am confused in whether i should go with WebApp->pgbouncer->Haproxy->pgcluster or with WebApp->Haproxy->pgbouncer->pgcluster approach.
Hey Manoj, I'm glad you found it useful!
Both of the approaches you outlined are valid, both have their pros&cons.
Option A:
WebApp->pgbouncer->Haproxy->pgcluster
Option B:
WebApp->Haproxy->pgbouncer->pgcluster
I am assuming that for A a pgbouncer would run on each application host.
I am assuming that for B a pgbouncer would run on each patroni host.
There are two main limitations:
1. When using HAProxy in the httpchk mode, such as shown here, HAProxy only knows the healthiness of the Patroni cluster member, it knows nothing about any pgbouncers in between HAProxy and patroni:
https://github.com/zalando/patroni/blob/master/haproxy.cfg
2. pgbouncer cannot be configured to check two different hosts for which one is alive. So either you would have to wrap the HAProxy in a virtual IP address or DNS record, or you have one HAProxy directly behind each pgbouncer on the same host.
With option A, in case of a failover in the patroni cluster, pgbouncer will handle the reconnections transparently for the application, i.e. as long as pgbouncer runs, the application would never need to reconnect.
With option B, the HAProxy really should consider whether pgbouncer is healthy, not only the patroni cluster member that pgbouncer is directed at. Otherwise HAProxy will send connections to a dead pgbouncer, while the database on the same host is still running fine.
If you put HAProxy on a seperate host, you should consider running two HAProxies, in case one goes down or needs maintenance. Then, you will need to have a way of always connecting to a healthy HAProxy. this could be done using keepalived and a virtual IP address or a DNS record. So that either the webapp or the pgbouncer always connects to the same hostname or IP and is always redirected to a healthy HAProxy.
If you want to limit the amount of hosts involved and don't want to deal with virtual IP addresses or DNS records, the easiest option is probably to use option A, and put both pgbouncer and HAProxy directly on the webapp server. So if either the webapp itself, or pgbouncer, or HAProxy die, you can simply switch over to the other webapp server.
If you have multiple webapp servers that all run simultaneously, it could be useful to have them all use the same pgbouncer (instead of one pgbouncer per webapp server). So in that case, the HAProxy would need to go in front of the pgbouncer (option B).
You see, there are a lot of things to consider and a lot of options to solve the different problems. I suggest that you start drawing up your current architecture and think about what happens if you put haproxy and pgbouncer in different places. What happens if the machines die, or if the processes themselves fail? And: how complicated do you want to make things? 🙂 There are some benefits to be had that warrant complicating things (with e.g. virtual IP addresses) but it is not always necessary.
Thanks Julian for your prompt and detailed answer. I will prefer to go with option A:
WebApp->pgbouncer->Haproxy->pgcluster. Now the thing is i have multiple webApps running in containers (running in 2 App nodes for HA & LB) and accessing the pg cluster through HAproxy which is running in another node(1st edge node). i will be adding HAproxy(2nd edge node) in cluster (HA for HAproxy) soon and will use the VIP. Now for pgbouncer, what will you recommend and at which node? my assumption is either i can install pgbouncer in both the nodes natively or using containers. I want to maintain the HA for pgbouncer too. Any further comments on this. email: manoj.kr.ghosh@gmail.com
You can run
1. pgbouncer on webapp host
2. pgbouncer on its own host
3. pgbouncer on haproxy host
In terms of RTT spent connecting to the pgbouncer, the best option is (1.) to put pgbouncer directly onto the host where the application runs.
For cases 1. 3. you will need to add the liveliness of pgbouncer (there is an SQL-like interface exhibited by pgbouncer itself where you can run something like "SHOW STATS" to determine healthiness) to the liveliness criteria for the host. So if either the webapp (1.), or haproxy (3.), or pgbouncer fail, you need to consider the host unhealthy in terms of HA.
Hi Julian. Could you please suggest any link or idea on how the 3 node etcd cluster will maintain failover/HA. In my setup 3 node etcd with 2 node pg cluster (using patroni) was working fine till all of the etcd instances were running. once the 2 nodes were down, patroni was unable to run further on the same node where etcd was running. with the errors like: "Max retries exceeded with url: /v2/machines (Caused by ReadTimeoutError("HTTPConnectionPool.." for the other 2 nodes.
The DCS clusters that use the RAFT protocol always require a majority of nodes to be up. If you want to be able to shut down two etcd (or consul, or...) nodes simultaneously, you will need more nodes total. You always need floor(n/2) 1 cluster members online, where n is the number of total cluster members.
This way, the etcd cluster is already highly available. But high availability for etcd does not mean you can loose n-1 cluster members (all but one). You can loose max. n-(floor(n/2) 1) cluster members.
The fact that patroni was unable to run is by design, so that you never end up with a split brain - consider that your etcd cluster might be partitioned. If patroni sees only a minority of etcd cluster members, it might be that the remaining cluster members are on the other side of the partition, and that there is another patroni who has managed to grab the leader key.
Thanks a lot Julian for this detailed clarification.
Hi, I can not find the sample config files in the above article. Also what is the setup for already running database. How do we configure without init bootstrap.
Thanks
Ahmed