Our PostgreSQL blog about “Speeding up count(*)” was widely read and discussed by our followers on the internet. We also saw some people commenting on the post and suggesting using different means to speed up count(*). I want to specifically focus on one of those comments and to warn our readers.
Table of Contents
As stated in our previous post, count(*) has to read through the entire table to provide you with a correct count. This can be quite expensive if you want to read through a large table. So why not use an autoincrement field along with max and min to speed up the process? Regardless of the size of the table.
Here is an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
test=# CREATE TABLE t_demo (id serial, something text); CREATE TABLE test=# INSERT INTO t_demo (something) VALUES ('a'), ('b'), ('c') RETURNING *; id | something ----+----------- 1 | a 2 | b 3 | c (3 rows) INSERT 0 3 test=# SELECT max(id) - min(id) + 1 FROM t_demo; ?column? ---------- 3 (1 row) |
This approach also comes with the ability to use indexes.
|
1 |
SELECT min(id), max(id) FROM t_demo |
… can be indexed. PostgreSQL will look for the first and the last entry in the index and return both numbers really fast (if you have created an index of course - the serial column alone does NOT provide you with an index or a unique constraint).
The question now is: What can possibly go wrong? Well … a lot actually. The core problem starts when transactions enter the picture. On might argue “We don't use transactions”. Well, that is wrong. There is no such thing as “no transaction” if you are running SQL statements. In PostgreSQL every query is part of a transaction - you cannot escape.
That leaves us with a problem:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
test=# BEGIN; BEGIN test=# INSERT INTO t_demo (something) VALUES ('d') RETURNING *; id | something ----+----------- 4 | d (1 row) INSERT 0 1 test=# ROLLBACK; ROLLBACK |
So far so good …
Let us add a row and commit:
|
1 2 3 4 5 6 7 8 |
test=# INSERT INTO t_demo (something) VALUES ('e') RETURNING *; id | something ----+----------- 5 | e (1 row) INSERT 0 1 |
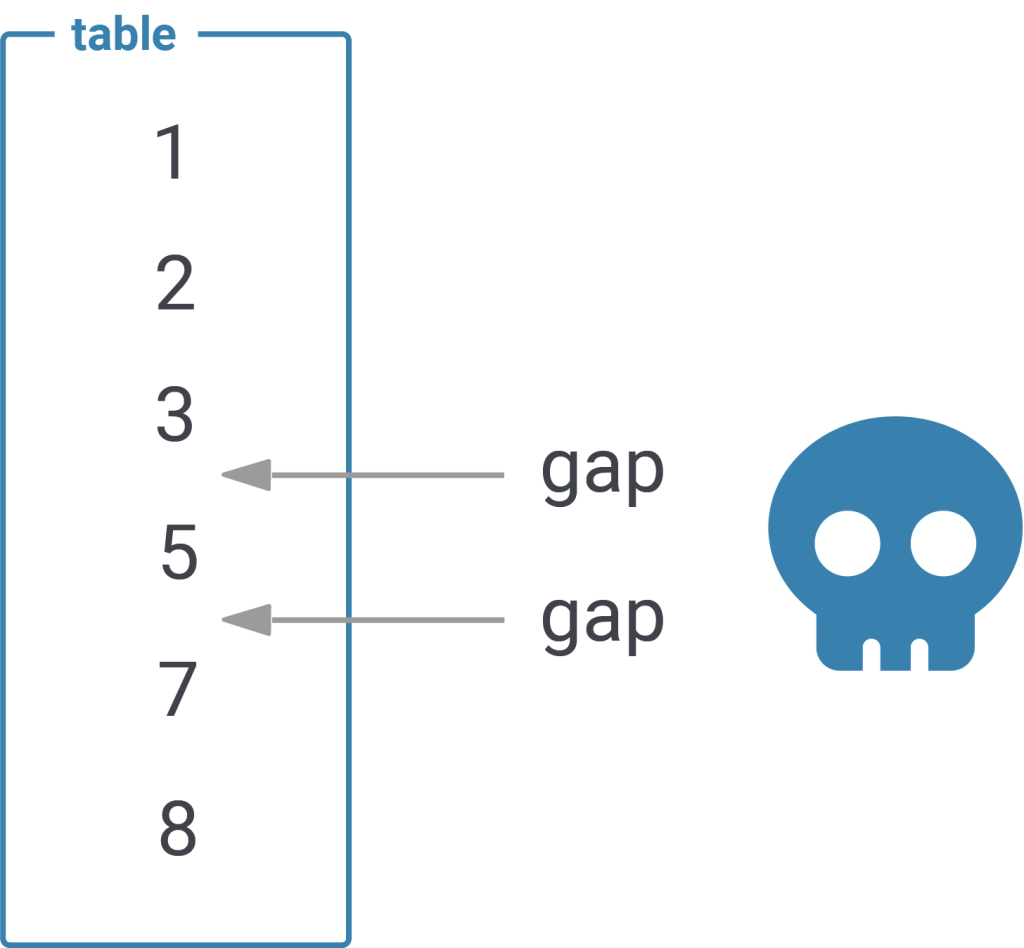
The important part is that a sequence DOES NOT assure that there are no gaps in the data - it simply ensures that the number provided will go up. Gaps are possible:
|
1 2 3 4 5 6 7 8 |
test=# SELECT * FROM t_demo; id | something ----+----------- 1 | a 2 | b 3 | c 5 | e (4 rows) |
In my example “4” is missing which of course breaks our “count optimization”:
|
1 2 3 4 5 |
test=# SELECT max(id) - min(id) + 1 FROM t_demo; ?column? ---------- 5 (1 row) |
What you should learn from this example is that you should NEVER use sequences to speed up count(*). To make it clear: In PostgreSQL count(*) has to count all the data - there is no way around it. You might be able to estimate the content of the table, but you won't be able to calculate a precise row count with any of those tricks.
If you want to take a look at Laurenz Albe's blog post, directly check it out on our website. If you want to learn more about performance in general check out our latest extension: pg_show_plans.
Are you saying that COUNT(*) does a serial read of the whole table? Wouldn't it be more efficient to count the number of entries in the primary key index?
well, this is more complex than meets the eye. the entire trouble here is related to "visibility". an index entry does not automatically translate to a 1 in the count. you got to figure out if the tuple is a.) there and b.) visible to your transaction. in addition to that traversing an index completely is more costly than just a plain sequential read. if your table is really really really broad you might actually see full index scans in rare cases but in general reading it all is a lot better (no random random I/O etc.)
To strike a lighter note here:
- You can get an (almost) index only scan in PostgreSQL by tuning autovacuum so that it processes the table often.
- With an index only scan you will be much faster in all but pathological cases.
But yes, it is somewhat tricky in PostgreSQL.
what a nice topic for one of my next posts. thanks guys !
I would have never thought to substitute a count with a max/min difference, rather a pg_stats.reltuples at least. However, there are edge cases when the max/min approach could work: append only tables or hose where a DELETE has been proibited by ACLs or triggers. I would not push towards these cases thought.
No!
As the article explains, even with only inserts a sequence value is "lost" if a transaction is rolled back (think "network outage").
I agree in principle that if you need a precise count, using the min max difference of an autoincrement column is not reliable.
However, using this min max differences may provide a good and fast estimate of the actual row count if your need does not require an exact count but some ball park figures.
For example, when I have a huge table with almost a million of rows added daily, and I need to create a schedule job to start deleting data that are roughly more than a month old before my server disk space hits the high water mark, it would be a good choice to use the min(auto_inc_id_column) to tell me the id of the oldest row, and find out if the timestamp of the record at id = max(id) - min(id) 100000 is more than a month old and delete all records within this range of ids between max(id) and max(id) - min(id) 100000. In doing so, I'm not trying to delete every not-to-be-retained row in one goal, but am trying to let the job runs many times throughout the day (maybe more often at night hrs) to delete the oldest set of records. We'll let the job fail if the record at id = max(id) - min(id) 1000000 doesn't exist due to some business use cases supported by the app might have introduced small id gaps in which this particular id is missing, but subsequent runs of the job will be deleting a different subset of oldest records covering such gaps as more records get added to the system. We are fine if we have retained slightly more than 30 days of records should the job fail more often than usual in some days and then some old records not yet deleted need be cleaned up only on the next day, as long as the retained records overall don't trigger the high water mark alert. In this scenario, we don't need an exact count like > 30 millions records to start deleting, but just some beginning and ending id's to start deleting ~100k records older than a month in batches; using the exact count approach may bring our system to a halt.