To dig a bit deeper into zheap and PostgreSQL storage technology in general I decided to provide some more empirical information about space consumption. As stated in my previous blog post about zheap is more efficient in terms of storage consumption. The reasons are:
Table of Contents
The question is: While those theoretical statements are true one wants to know what this means in a real-world scenario. This blog will shed some light on this question and give you some more empirical insights as to what is to be expected as soon as zheap is production-ready (which it is NOT as of October 2020).
To show the differences in storage consumption I have created some sample data. To make it fair I have first added data to a temporary table which is in memory. This way there are no undesired side effects:
|
1 2 3 4 5 6 7 8 |
test=# SET temp_buffers TO '1 GB'; SET test=# CREATE TEMP TABLE raw AS SELECT id, hashtext(id::text) as name, random() * 10000 AS n, true AS b FROM generate_series(1, 10000000) AS id; SELECT 10000000 |
10 million rows will roughly translate to half a gigabyte of data:
|
1 2 3 4 5 6 |
test=# d+ List of relations Schema | Name | Type | Owner | Persistence | Size | Description -----------+------+-------+-------+-------------+--------+------------- pg_temp_5 | raw | table | hs | temporary | 498 MB | (1 row) |
A standard temporary table is absolutely fine for our purpose.
One of my favorite features in PostgreSQL is CREATE TABLE … LIKE …. It allows you to quickly create identical tables. This feature is especially useful if you want to clone a table containing a large number of columns and you don't want to to list them all, manually create all indexes etc.
Copying the data from "raw" into a normal heap table takes around 7.5 seconds:
|
1 2 3 4 5 6 7 8 |
test=# timing Timing is on. test=# CREATE TABLE h1 (LIKE raw) USING heap; CREATE TABLE Time: 7.836 ms test=# INSERT INTO h1 SELECT * FROM raw; INSERT 0 10000000 Time: 7495.798 ms (00:07.496) |
Let us do the same thing. This time we will use a zheap table. Note that to use zheap one has to add a USING-clause to the statement:
|
1 2 3 4 5 6 |
test=# CREATE TABLE z1 (LIKE raw) USING zheap; CREATE TABLE Time: 8.045 ms test=# INSERT INTO z1 SELECT * FROM raw; INSERT 0 10000000 Time: 27947.516 ms (00:27.948) |
As you can see creating the content of the table takes a bit longer but the difference in table size is absolutely stunning:
|
1 2 3 4 5 6 7 8 |
test=# d+ List of relations Schema | Name | Type | Owner | Persistence | Size | Description -----------+------+-------+-------+-------------+--------+------------- pg_temp_5 | raw | table | hs | temporary | 498 MB | public | h1 | table | hs | permanent | 498 MB | public | z1 | table | hs | permanent | 251 MB | (3 rows) |
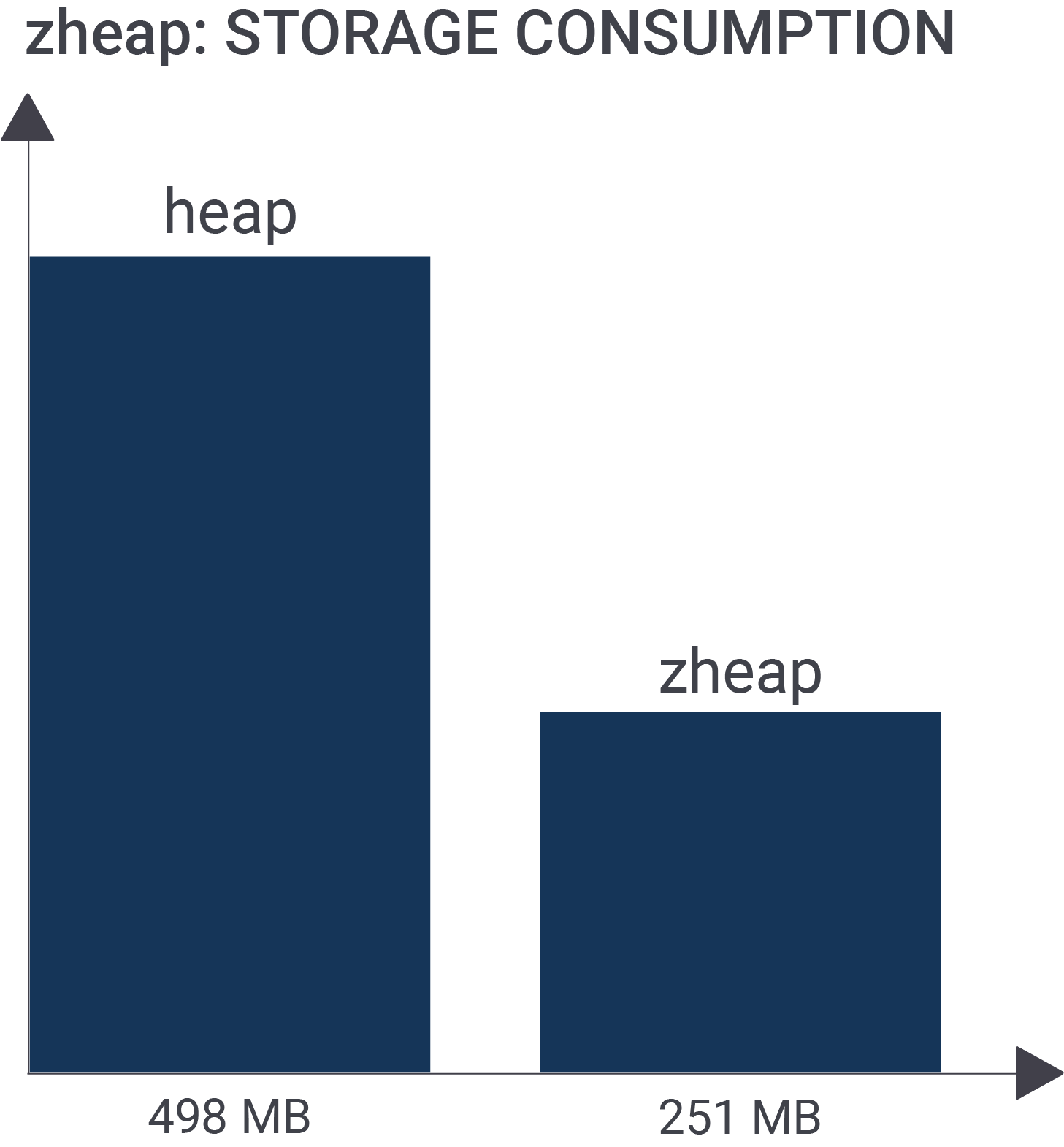
The zheap table is roughly 50% smaller than the normal PostgreSQL storage format. The main question naturally arising is: Why is that the case? There are basically two important factors:
Let us consider the tuple header first: The new tuple header is only 5 bytes which is almost 20 bytes less per row. That alone saves us around 200 MB of storage space. The reason for the smaller tuple header is that the visibility information has been moved from the row to the page level ("transaction slots"). The more columns you've got the lower the overall percentage will be but if your table is really narrow the difference between heap and zheap is very significant.
NOTE: Reduced storage consumption is mostly an issue for tables containing just a few columns - if your table contains X00 columns it is less of an issue.
UPDATE has traditionally been an important thing when talking about zheap in general. So let us see what happens when a table is modified:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
test=# BEGIN; BEGIN test=*# SELECT pg_size_pretty(pg_relation_size('z1')); pg_size_pretty ---------------- 251 MB (1 row) test=*# UPDATE z1 SET id = id + 1; UPDATE 10000000 test=*# SELECT pg_size_pretty(pg_relation_size('z1')); pg_size_pretty ---------------- 251 MB (1 row) |
In my case the size of the row is identical. We simply want to change the ID of the data. What is important to notice here is that the size of the table is identical. In case of heap the size of the data file would have doubled.
To support transactions UPDATE must not forget the old rows. Therefore the data has to be "somewhere". This "somewhere" is called "undo":
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[hs@hs-MS-7817 undo]$ pwd /home/hs/db13/base/undo [hs@hs-MS-7817 undo]$ ls -l | tail -n 10 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003EC00000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003ED00000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003EE00000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003EF00000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003F000000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003F100000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003F200000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003F300000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003F400000 -rw-------. 1 hs hs 1048576 Oct 8 12:08 000001.003F500000 |
The undo area contains a couple of files (1 MB each) holding the undo data which is necessary to handle rollback properly (= putting the old data back into the table).
In other words: Being able to handle transactions is not free - the space needed to do that is simply handled in a different way.
If you are using a normal heap ROLLBACK is basically free because a transaction can simply leave all its obsolete trash behind. Not so if you are using zheap to store data.
Let us compare and see:
|
1 2 3 4 5 6 7 8 9 |
test=# BEGIN; BEGIN Time: 0.309 ms test=*# UPDATE h1 SET id = id - 1 WHERE id < 100000; UPDATE 99999 Time: 741.518 ms test=*# ROLLBACK; ROLLBACK Time: 0.181 ms |
As you can see the ROLLBACK is really quick - it does basically nothing. The situation is quite different in case of zheap
|
1 2 3 4 5 6 7 8 9 |
test=# BEGIN; BEGIN Time: 0.151 ms test=*# UPDATE z1 SET id = id - 1 WHERE id < 100000; UPDATE 99998 Time: 1066.378 ms (00:01.066) test=*# ROLLBACK; ROLLBACK Time: 41.539 ms |
41 milliseconds is not much but it is still a lot more than a fraction of a millisecond. Of course, things are slower but the main issue is that zheap is all about table bloat. Avoiding table bloat has major advantages in the long run. One should therefore see this performance data in a different light. One should also keep in mind that COMMIT is (in most cases) ways more likely than ROLLBACK. Thus putting a price tag on ROLLBACK might not be so problematic after all.
If you want to give zheap a try we suggest taking a look at our Github repo. All the code is there. At the moment we have not prepared binaries yet. We will soon release Docker containers to make it easier for users to try out this awesome new technology.
We again want to point out that zheap is still in development - it is not production-ready. However, this is a really incredible technology and we again want to thank Heroic Labs for the support we are receiving. We also want to thank EDB for the work on zheap they have done over the years.
If you want to learn more about storage efficiency, alignment etc. we recommend checking out my blog post about column order. In addition, if you want to know more about specific aspects of zheap feel free to leave a comment below so that we can maybe address those issues in the near future and dedicate entire articles to it.
Leave a Reply